
运行时下的水平越权漏洞检测
@turn1tup
1.前言
今年上半年笔者在着手于尝试检测Java应用的逻辑漏洞,整个项目在逐步完善并趋于成熟了之中。方案的水平越权检测逻辑其实是比较复杂的,里程上分为单机版与微服务版,微服务版需要解决跨进程数据跟踪问题,而本文对单机版稍作分享,欢迎大家进行探讨。
这里也提一嘴,目前项目是基于蚂蚁安全的切面底座,这减少了笔者在字节码、底层处理方面的工作,至少减少了前期三成以上的工作量,此外由于切面框架成熟丰富,也带来了不少开发便利;笔者得以有更多精力承载此项目,通常只需要关注自己的应用层如何实现的。
2.定义问题
在具体讲解水平越权漏洞检测之前,我们来大致聊聊整个逻辑漏洞问题,对逻辑漏洞进行相关的定义。
未明确问题之前,我们无法知晓自己能做什么(能检测什么逻辑漏洞)以及要怎么做。在具备相关的知识技能前提下,笔者在此梳理过程中发现,“水平越权漏洞”可能可以通过运行时(被动IAST)进行检测,且这种检测方案具备相当的“诱惑力”。
逻辑漏洞的分类在大的方向上有 未鉴权、垂直越权、水平越权:
- 未鉴权:某个接口无需用户登陆凭证即可访问、允许匿名访问,因此解决未鉴权问题一方面需要识别接口是否为未鉴权接口,另外一方面要识出接口是否为“敏感接口”。前者在统一网关管控路径权限的应用中倒不是问题,拿到配置就可以了解接口的鉴权情况,麻烦点还是在后者上;对于后者我们可以检测HTTP响应报文中的敏感数据来做这个事情,但这需要主动发包/流量重放/或是处理流量响应报文。
- 垂直越权:当用户拥有“管理”类的职权时,这些管理类的后台接口影响的数据的查询与更新非围户来发生,而是通过组、部门、公司 等单一、多个或组合的形式来鉴别用户职权并产生 查询、更新的行为。垂直越权漏洞通过主动扫描(扫描器维护不同职权用户凭证)来进行挖掘更好,这个问题在笔者看来是最难解决的。此外,由于业务复杂情况,需要主动发包的方案都让人担忧,笔者也就暂时不纳入考虑。
- ·水平越权:在普通用户接口下,绝大部分数据围绕用户产生,数据的查询、更新行为通常伴随某用户,相关接口在查询(并返回给前端)或更新前需要检查当前操作者是否数据所属用户,开发者在获取/更新数据时,没有对数据所属用户进行检查,则会存在“水平越权”问题。水平越权问题下的逻辑关系似乎较为简单,其中有条“线”,笔者 也是后知后觉,即一切最后都会落到表的结构关系中。
通过运行时来检测水平越权漏洞,可以做到不主动发包,正常业务行为即可触发漏洞检测过程,因此这个方案十分具有诱惑力,另外,在完善过后,还会有更多利用场景,此外这似乎是一个有趣有挑战有创新的东西。
3.问题模型
本节讲述一下笔者认为的问题模型,而这个模型中会存在各个实体,在此讲述过程中也绘画出方案的思路轮廓。
首先,得益于开发语言成熟的开发框架,使得运行时的数据跟踪更为简单、可适配,而检测水平越权漏洞的重点之一就是需要和DAO层打交道。对于一个SQL查询来说,封装到DAO层,我们通过适配DAO框架(mybatis)可以跟踪每个对象、参数到sql执行的入参与执行结果。
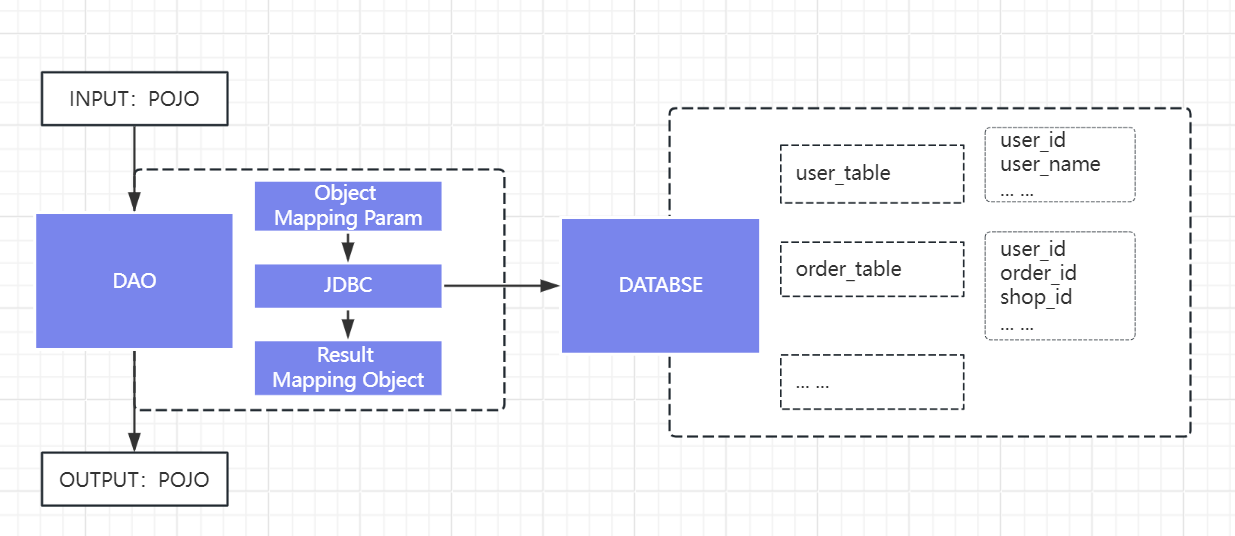
水平越权下的实体:
- 数据库表:表在设计时已经含有了“用户”与“用户数据”关系的这一逻辑,而这个逻辑是通过关联user_id一类的表字段来进行的。
- 用户表:unique key一类的表字段都进行关注,都具有和user_id具备“标记同一个用户的功能”,本文记为 owner column
- 用户数据表:包含owner column的表,而某些表需要人工手动排除,如商品评论表,包含user_id这一owner column,但商品评论信息的查询不需要鉴别用户权限。
- 被忽略的表:不包含owner column的表默认被忽略,或人工手动将其他表添加到忽略中,被忽略的表表示不需要进行水平越权检测。
- SQL语句:SQL执行在 JDBC层,而通过DAO我们得以将其与业务层的对象进行关联
- SQL类型:存在update、query两种SQL执行,针对query,当且其结果输出给到前端时,我们才能判断其a是否存在越权,为了简化表述,本文后续只讨论query。
- 分层:
- 控制层:应用在fliter/interceptor控制层对用户进行了鉴权,走到业务层的都是有效凭证的用户(在水平越权视角下)
- 业务层:业务层可获取缓存的凭证/对象,操作DAO层时需要利用缓存的凭证与DAO交互,避免单纯采信用户的输入导致越权(用户访问的数据与所属用户不符)
- DAO层:封装SQL执行,且DAO层的输入与输出对于运行时的RASP/IAST都是易得的
- 数据类型:与 白盒/被动IAST 一样,大的框架上是需要跟踪数据的传播,而说到数据的传播,经典的概念也随之而来(source/sink)
- source:来自用户的输入,默认是不可信任的
- pure:来自缓存的凭证/对象,或是被pure影响的数据也可能会标记未pure,表示这是一个可信任的数据
- sink:query情况下的漏洞检测点最终在controller mapping方法的返回结果出,检查该结果对象是否存在字段内容值来源于越权查询出的数据。
- DAO层与业务操作者之间进行数据流转,DAO层的数据来源可能是HTTP输入、其他DAO Query的结果、缓存的凭证等等,在数据流转的过程中,我们进行数据跟踪,根据算法逻辑对其进行标记
SQL语句中的taint:普通用户接口下的业务层代码和“用户数据表”打交道时就会产生是否存在水平越权的问题,而这个代码最终体现在sql执行上的约束上,我们需要跟踪约束项的数据来源(静态代码或运行时中,针对数据流,从用户输入source到污点sink过程中可能会存在流中继,流中继的上游入口数据可以简称taint)。
- 约束项taint:这里有两个要点需要理解,其一,SQL语句中的约束项视为taint,因此其对应着具体的表列;其二,不是所有的taint都需要关注,通常unique column/owner column外的其他列不需要关注。
- SQL约束:SQL约束有三个场景
- 场景1,开发者需要通过SQL执行的约束where指定owner column值来避免数据被非属用户访问(因此,SQL约束也应该是我们运行时跟踪的关键点,当然,具体实现上不会了解约束的语义,只解析出约束项)。demo sql语句为,select * from order where user_id = ?
- 场景2,通过非onwer column而是unique column来约束SQL执行,那么,unqiue column指定的数据值的来源必然是场景1
- 场景3,此外,也可能存在SQL执行语句未作约束的情况,普通用户接口下直接查询所有用户数据,此情况下可对未做unique column/owner column约束的SQL执行进行告警
4.数据跟踪
数据跟踪包括几个关键要点:对象拆分、对象标记、DAO流中继
- 对象拆分:除了被动IAST中关注的情况List/Set/…,对于POJO/Bean对象,我们也需要进行拆分,获取到其各个字段值的对象;通常POJO的拆分只需要在source、DAO 这两个地方进行即可。
- 对象标记:维护 SourceMap、PureMap、TaintMap分别记录对象是否为soure、是否为pure、是否为query的结果数据,被动IAST的数据跟踪这一抽象话术,落到实际来看,其中一点就是对象标记。v
- DAO流中继:DAO是一个上层封装,底下会涉及到许多关键逻辑
- 分析DAO执行的SQL语句:对于入参,如果其是SQL约束项,解析出其表列,并从后台获取该表列的“标记”(owner/unique /是否ignore);对于查询结果,解析出查询结果数据对应的表列(这么做的具体原因稍后说明)
- 依赖关系map:DAO结果对象通常是POJO,由于其是从数据库查询出来的,是“一体”的,因此保存它们的一体关系,当其一者的标记发生变化时,则应都进行同样的标记变化。。
当pure数据与其他类型数据发生关系(数据传播、流程控制)时我们需要关注的,因为这意味着可能有新的pure数据产生,项目中的核心逻辑之一也是在这一点的处理上:
- DAO的数据传播:如果SQL执行中的约束项(unique/owner)是pure,则SQL执行结果也为pure;此外,如果SQL执行的其他入参的表列与执行结果的表列一直,则该入参对象也标记为pure
- 流程控制:当一个数据对象与pure进行equals对比且return为true,则该数据对象也被标记为pure。这个判断逻辑的依据是,我们假设这里发生会流程控制(与pure对比,false就中断流程/抛异常)。如查询订单,订单号来自HTTP输入,开发者应先查询这个订单的所属用户,之后有 “订单用户ID”.equals(“凭证用户ID”) 的判断,当结果为true时 “订单用户ID” 才能被使用,否则应抛出异常。
5.结语
运行时检测下,具备被动IAST一样的优势,无需构建扫描器进行发包,部署在测试环境随业务测试进行即可,也具有被动IAST一样的缺点,不适合部署在生产环境(消耗性能)。此外,项目方案技术难度较高,需要适配的框架较多,在技术上,通常只跟踪引用类型数据(因此建议POJO Class的字段不要使用非boxed的基本数据类型,如int修改为Integer),否则误报率会提升。
本文想着把这块思路稍作分享,但似乎有些复杂,导致写下来可能难以做到易懂,其中的逻辑一环套一环,写起来也是麻烦。但根本上来说,项目方案就是利用了数据库中用户表与其他数据表的关系,这是最底层的基石。
此前的单机版本通过高starts开源项目mall4j测试,测试中对该商场系统的各个普通用户接口进行了全量测试(接口无越权、接口修改为有越权 两面测试),阶段性来看方案是可行的。
而目前笔者在改造为微服务版本,为了应对微服务问题 ,IAST各处逻辑需要重构到云端进行处理;此外,需要适配HTTP Client/Server、内容解析等等从而实现跨进程数据跟踪问题。当然,这些问题也基本一一解决了,后面完成云端后台的算法处理后,可以开始在业务方进行部署测试了,也期待后续在业务方的测试情况吧~不过,相信会存在很多问题…